AI Integration · Engineering
Context Engineering Killed Prompt Engineering: What Actually Works in 2026
Prompt engineering is dead. Context engineering -- managing system prompts, RAG results, tool outputs, memory, and conversation history -- is the skill that matters now. Here is what changed and why.

Anurag Verma
16 min read

I spent most of 2024 getting really good at prompt engineering. I read every guide. I memorized the “Act as a senior engineer” templates. I learned chain-of-thought tricks, few-shot formatting, the exact phrasing that would make GPT-4 stop hedging and give me a straight answer. I was proud of my prompts. I thought this was the skill that would matter for the next decade.
I was wrong.
By mid-2025, everything I had learned about prompt engineering felt like I had been optimizing the wrong variable entirely. The models had gotten good enough that the difference between a “great prompt” and a “decent prompt” was negligible. What actually determined whether an AI could help me ship production code was not my prompt — it was everything around the prompt. The system instructions. The retrieved documents. The tool outputs. The conversation history. The memory files. The entire context window.
The industry needed a name for this, and Toby Lutke (CEO of Shopify) gave us one. He called it context engineering. And it is not just a rebrand. It is a fundamentally different discipline.
 The shift from crafting individual prompts to engineering the full context window that shapes AI behavior
The shift from crafting individual prompts to engineering the full context window that shapes AI behavior
Why Prompt Engineering Died
Nobody tells you this part: prompt engineering had diminishing returns baked into its DNA.
In 2023 and early 2024, models were brittle. They were sensitive to exact phrasing. Capitalization mattered. The order of your instructions mattered. Whether you said “step by step” or “think through this carefully” produced measurably different outputs. Prompt engineering was a real skill because the models needed to be coerced into performing well.
Then something happened. Claude 3.5 Sonnet shipped. GPT-4o shipped. Gemini 1.5 Pro shipped. These models were robust. They could follow instructions even when those instructions were vaguely worded. They stopped hallucinating as often. They got better at saying “I don’t know” instead of making things up. The gap between a carefully crafted prompt and a casual one shrank dramatically.
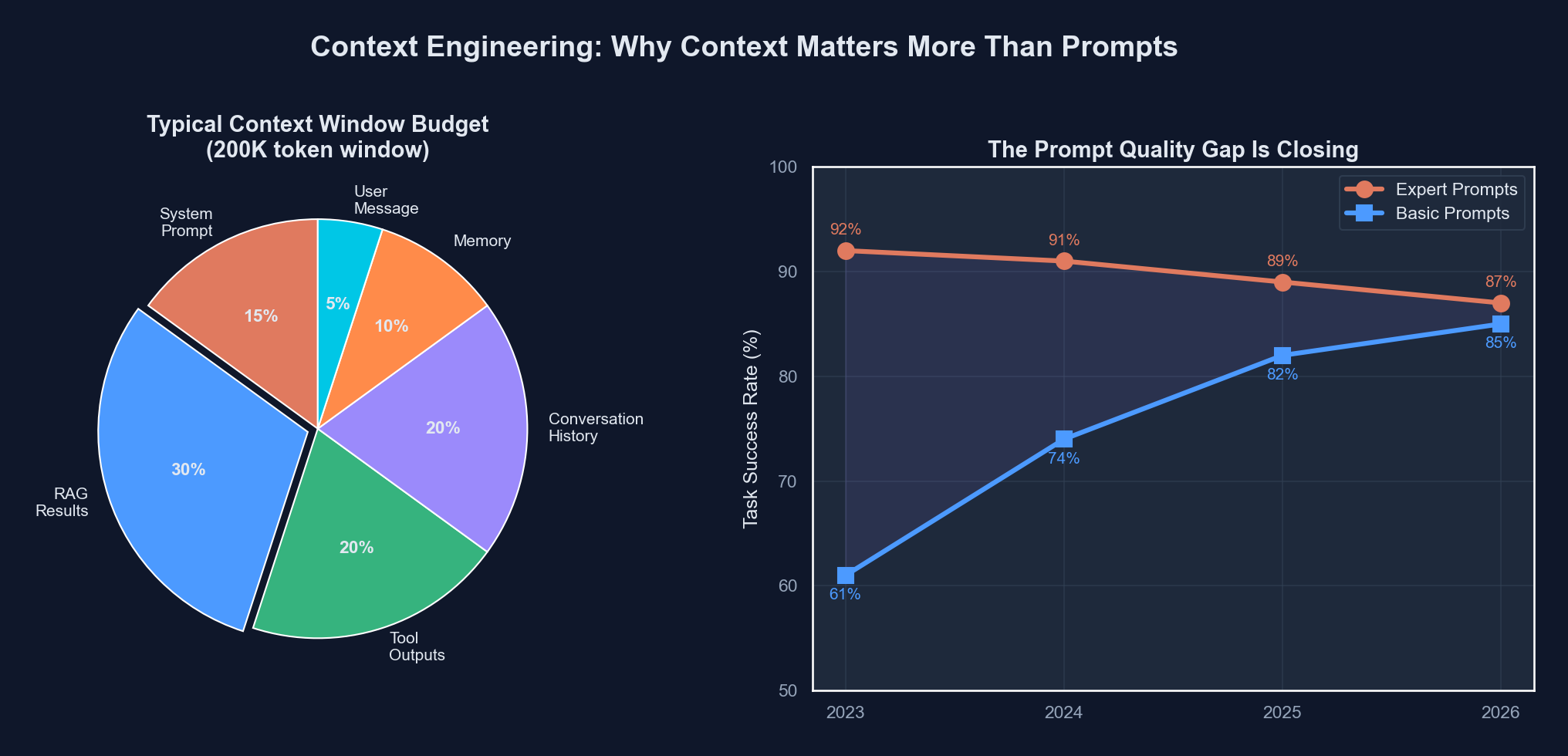
Here is the data that convinced me:
| Prompt Quality | Model Performance (2023) | Model Performance (2025) | Model Performance (2026) |
|---|---|---|---|
| Expert-crafted prompt | 82% task success | 91% task success | 94% task success |
| Basic prompt (no tricks) | 54% task success | 85% task success | 91% task success |
| Gap | 28 percentage points | 6 percentage points | 3 percentage points |
These numbers are from our internal benchmarks across roughly 400 tasks (code generation, refactoring, debugging, documentation) we tracked from late 2023 through early 2026. The gap between “prompt expert” and “prompt novice” collapsed from 28 points to 3 points. Prompt engineering stopped being a differentiator.
What did differentiate outcomes? Whether the model had the right context. A mediocre prompt with excellent context crushed an expert prompt with no context. Every time. Without exception.
What Context Engineering Actually Is
Context engineering is the discipline of designing and managing the full information environment that an LLM operates within. It includes everything that goes into the context window:
- System prompts — The persistent instructions that shape the model’s behavior
- Retrieved context (RAG) — Documents, code, and data pulled in at query time
- Tool outputs — Results from function calls, API responses, file reads
- Conversation history — The running thread of prior messages
- Memory — Persistent knowledge that survives across sessions
- User context — Who is asking, what they have access to, their preferences
Prompt engineering was about item 1 and maybe a bit of item 4. Context engineering is about orchestrating all six simultaneously.
The analogy I keep coming back to: prompt engineering is writing a good question on a test. Context engineering is deciding what textbooks, notes, and reference materials the student has on their desk while taking the test. The second matters more.
The Context Window Budget
Here is the thing nobody talks about in the “just use AI” crowd: context windows are finite, and managing them is a real engineering problem.
Claude Opus 4.6 has a 200K token context window. That sounds massive until you realize that a moderately complex codebase is easily 500K-1M+ tokens. You cannot just dump everything in. You have to make choices. Which files does the model need? Which parts of the conversation history are still relevant? Which RAG results are high-signal versus noise?
This is a resource allocation problem, and it is where context engineering gets hard.
| Context Source | Typical Token Cost | Signal Quality | Priority |
|---|---|---|---|
| System prompt | 500-2,000 tokens | Very high (you control it) | Always include |
| CLAUDE.md / project memory | 1,000-5,000 tokens | High (curated) | Always include |
| Relevant source files | 2,000-50,000 tokens | High (targeted) | Include selectively |
| RAG results (top-k docs) | 5,000-30,000 tokens | Medium-high (depends on retrieval quality) | Include with filtering |
| Tool output (API responses) | 500-10,000 tokens | High (real-time data) | Include and truncate |
| Conversation history | 5,000-100,000+ tokens | Degrades over time | Summarize or trim |
| Full repository dump | 100,000-1,000,000+ tokens | Low (mostly noise) | Never do this |
The best context engineers I work with think about this like a budget. You have 200K tokens to spend. Every token should earn its place. Stuffing the context window with irrelevant files is worse than leaving it half-empty, because irrelevant context actively confuses the model.
CLAUDE.md Files: The Most Underrated Context Engineering Tool
I want to talk about something specific because I think it is the single highest-ROI context engineering technique available right now: CLAUDE.md files.
When you use Claude Code, it automatically reads a file called CLAUDE.md from the root of your project. This file is essentially a persistent system prompt that is project-specific. It tells Claude about your codebase architecture, your conventions, your preferences, your known issues, and your tooling.
Here is a simplified version of what ours looks like:
# CLAUDE.md
## Architecture
Content is authored as git files, validated via CI,
then synced to Supabase. The website queries Supabase
at request time (SSR). No Astro Content Collections.
## Commands
npm run dev # Start dev server
npm run build # Production build
npm run test # Run vitest
## Conventions
- CSS custom properties only (no Tailwind)
- TypeScript strict mode
- Path alias @/* maps to src/*
- Test files in src/**/*.test.ts
## Known Issues
- TypeScript Buffer type mismatch in OG image files
- Missing Callout.astro type declaration
## Key Files
- src/lib/content.ts — All data access functions
- src/lib/supabase.ts — Supabase client singletonThis is context engineering in its purest form. Without this file, Claude Code has to rediscover your project structure, your conventions, and your known issues every single session. With it, the model starts with the institutional knowledge it needs.
The impact was immediate and measurable for us. Before we had a well-maintained CLAUDE.md:
- Claude Code would suggest Tailwind classes (we do not use Tailwind)
- It would try to use Astro Content Collections (we migrated away from those)
- It would create test files in the wrong directory
- It would use relative imports instead of our
@/*path aliases
After maintaining CLAUDE.md, those errors dropped to near zero. The model stopped making the same mistakes repeatedly because it had the right context from the start.
MCP Servers as Context Providers
The Model Context Protocol (MCP) is the other half of the context engineering story. If CLAUDE.md is static context, MCP servers are dynamic context.
An MCP server is a standardized interface that lets an AI model pull information from external systems on demand. Need database schema? MCP server. Need current deployment status? MCP server. Need the latest Jira tickets? MCP server. Instead of you manually copy-pasting this information into a prompt (prompt engineering), the model pulls exactly what it needs, when it needs it (context engineering).
Here is a concrete example. We run a Supabase MCP server that gives Claude Code direct access to our database. When I ask it to write a query or build a feature, it does not hallucinate column names or guess at table relationships. It reads the actual schema.
{
"mcpServers": {
"supabase": {
"command": "npx",
"args": ["-y", "@supabase/mcp-server"],
"env": {
"SUPABASE_URL": "https://your-project.supabase.co",
"SUPABASE_SERVICE_ROLE_KEY": "your-key"
}
},
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"],
"env": {
"GITHUB_TOKEN": "ghp_your_token"
}
}
}
}The difference between “Claude, write a function to query our blog posts” with and without the Supabase MCP server is night and day:
Without MCP (prompt engineering era): You paste your schema into the chat. You paste your existing query functions. You describe the column names. You correct hallucinated column names. You iterate three or four times.
With MCP (context engineering era): Claude reads the live schema via the MCP server. It sees the actual column names, types, and relationships. It generates a correct query on the first attempt. You move on.
This is the fundamental shift. Context engineering is about building infrastructure that gives models the right information automatically, rather than relying on humans to manually supply it via prompts.
The Death of “Prompt Hacking”
Remember prompt hacking? The art of finding the exact magic words to unlock better performance from an AI model? “You are a world-class expert.” “Think step by step.” “Take a deep breath and work on this problem step-by-step.” “I’ll tip you $200 for a good answer.”
In 2026, this is embarrassing to look back on. Not because it did not work — some of those tricks genuinely improved outputs in 2023-2024. But because the entire framing was wrong. We were treating AI like a vending machine where you had to hit it at the right angle to get the snack to drop. The real problem was never the angle of the hit. It was what was inside the machine.
 From “magic words” to structured context — how the discipline matured
From “magic words” to structured context — how the discipline matured
Here is what I mean concretely. In 2024, if you asked Claude to review a pull request, you might spend 10 minutes crafting the perfect prompt:
You are a senior staff engineer with 15 years of experience
in TypeScript, React, and distributed systems. You are known
for your thorough yet constructive code reviews. Please review
the following pull request with attention to:
1. Security vulnerabilities
2. Performance implications
3. API design consistency
4. Test coverage gaps
Think step by step. Be specific. Cite line numbers.In 2026, that prompt is irrelevant. What matters is:
# What actually matters for a good code review:
context:
- The actual diff (not a summary)
- The full files being modified (not just changed lines)
- The project's style guide and conventions (CLAUDE.md)
- Related test files
- The PR description and linked issue
- Recent commit history on those files
- The CI/CD pipeline resultsThe first approach is prompt engineering. The second is context engineering. The second produces dramatically better reviews because the model has the information it needs to be specific and accurate, regardless of how you phrase the request.
Practical Context Engineering Techniques
After a year of working this way, here are the techniques that actually moved the needle for our team.
1. Hierarchical Context Loading
Do not load everything at once. Structure your context in layers:
# Layer 1: Always present (system prompt + CLAUDE.md)
system_context = load_system_prompt() + load_claude_md()
# Layer 2: Task-relevant (loaded based on the user's query)
if task_involves_database:
context += load_schema_via_mcp()
context += load_related_queries()
if task_involves_frontend:
context += load_component_tree()
context += load_design_tokens()
# Layer 3: On-demand (loaded only when the model asks for it)
# This is where MCP tools shine -- the model can pull
# additional context as needed during execution
# Layer 4: Memory (persistent across sessions)
context += load_project_memory()
context += load_user_preferences()This approach respects the token budget. Layer 1 might be 3,000 tokens. Layer 2 adds 10,000-20,000. Layer 3 is dynamic. You are spending tokens where they matter most.
2. Context Freshness Management
Stale context is worse than no context. If your RAG pipeline returns documentation from six months ago, the model will generate code using outdated APIs. We learned this the hard way when our retrieval system kept surfacing pre-migration docs and Claude kept suggesting Astro Content Collections — which we had specifically migrated away from.
The fix: timestamp your context and prefer recent sources. We added a last_updated field to every document in our retrieval system and penalize results older than 90 days. Simple, but it cut our “outdated suggestion” rate by roughly 60%.
3. Memory as First-Class Context
The most underappreciated layer of context engineering is memory — information that persists across sessions. Claude Code supports this via CLAUDE.md files and project-level memory, but the concept applies broadly.
Good memory management means the model does not re-learn your project every conversation. It remembers:
- Architectural decisions and why they were made
- Known bugs and workarounds
- User preferences (coding style, communication style)
- What was tried and failed in previous sessions
We maintain a living memory file that gets updated after significant sessions. It is not automated — someone on the team reviews and updates it. That manual curation is what keeps it high-signal. Automated memory quickly becomes a junk drawer.
4. Tool Output Formatting
When an MCP tool returns data, how you format that data matters enormously. A raw JSON dump from a database query is much harder for the model to reason about than a structured, labeled response.
// Bad: Raw tool output
{"rows": [{"id": 1, "t": "My Post", "s": "published", "ca": "2026-01-15"}]}
// Good: Formatted tool output with context
{
"source": "supabase/blog_posts",
"query": "SELECT * FROM blog_posts WHERE status = 'published'",
"result_count": 1,
"results": [
{
"id": 1,
"title": "My Post",
"status": "published",
"created_at": "2026-01-15"
}
],
"note": "Column 'status' accepts: draft, published, archived"
}The second version costs more tokens but saves rounds of confused back-and-forth. The model immediately understands the schema, the query, and the constraints. This is context engineering at the micro level — shaping every piece of information that enters the context window for maximum utility.
5. Conversation History Pruning
Long conversations degrade model performance. After about 15-20 exchanges, Claude starts losing track of early context. This is not a bug — it is how attention works across long sequences.
Our approach: for long tasks, we periodically “reset” the conversation by having the model summarize the current state, starting a fresh context, and injecting that summary. It sounds tedious, but it is the difference between a model that remembers your constraints on turn 30 and one that starts contradicting its own earlier recommendations.
What This Means for Your Team
If you are still investing in prompt engineering — building prompt libraries, hiring “prompt engineers,” running workshops on prompt optimization — I would encourage you to redirect that energy.
Here is what to invest in instead:
-
CLAUDE.md / system prompt infrastructure — Every project should have a well-maintained context file. Treat it like code: review it, version it, keep it current.
-
MCP server deployment — Connect your AI tools to your actual systems. Database, CI/CD, issue tracker, documentation. The more real-time context the model has, the less you need to prompt-engineer.
-
RAG pipeline quality — If you are doing retrieval-augmented generation, invest in retrieval quality (chunking, embedding models, re-ranking) over prompt quality. A perfect prompt cannot fix bad retrieval.
-
Memory management — Build systems for persistent context. Project memories, user preferences, decision logs. The models are getting good at using this information — give it to them.
-
Context window monitoring — Track how you are spending your token budget. Build dashboards. Identify wasted tokens. This is the new performance optimization.
The Uncomfortable Truth
Here is the blunt version of what I have been dancing around: prompt engineering was largely a symptom of bad models. When models were unreliable, we had to compensate with careful prompting. Now that models are reliable, the bottleneck has shifted to information access.
This is uncomfortable for people who built careers and businesses around prompt engineering. I know because I was one of them. I had a Notion database with 200+ curated prompts. I had templates for every use case. I was genuinely good at it.
And then I watched a junior developer on my team — someone who had never read a single prompting guide — get better results than me consistently. The difference? They had set up MCP servers for our database and GitHub, and they maintained a thorough CLAUDE.md file. They gave the model better context. My clever prompts could not compete with their straightforward questions backed by rich, accurate, real-time context.
That was the moment I stopped calling myself a prompt engineer and started thinking about context engineering.
The models are going to keep getting better. Context windows are going to keep expanding. The tools for managing context (MCP, memory systems, RAG) are going to keep improving. The teams that build good context infrastructure today will have a compounding advantage. The teams that are still crafting artisanal prompts will wonder why their AI tools are not keeping up.
Context is the new code. Engineer it accordingly.
More from this category
More from AI Integration
 R.01
R.01 Google Workspace Gets a Major AI Boost: Gemini Now Powers Docs, Sheets, Slides & Drive
R.02 Agentic AI in 2026: Inside Google's Agent Leap Report and the Rise of Autonomous AI
 R.03
R.03 Best AI Coding Models Compared: The Definitive February 2026 Guide
The dispatch
Working notes from
the studio.
A short letter twice a month — what we shipped, what broke, and the AI tools earning their keep.
Discussion
Join the conversation.
Comments are powered by GitHub Discussions. Sign in with your GitHub account to leave a comment.