Cloud & Infrastructure · Networking
Service Mesh in 2026: Do You Actually Need Istio, Linkerd, or Cilium?
Service meshes promise secure, observable microservice communication. But most teams that adopt one do so before they need it. Here is how to decide, and what each option actually costs you.

Anurag Verma
9 min read

Sponsored
Most teams that adopt a service mesh do it too early. They read about mTLS and distributed tracing, watch a conference talk where Google engineers explain how Istio runs at planet scale, and then spend three months wrangling CRDs for a system that handles 50 requests per second.
Service meshes are genuinely useful. They solve real problems. But those problems need to exist before the solution is worth its operational weight.
Here is a clear-eyed look at what service meshes actually do, what each major option costs you, and the specific thresholds where adopting one starts to make sense.
What a Service Mesh Actually Does
A service mesh inserts a proxy (a sidecar, or increasingly an eBPF hook in the kernel) alongside every workload in your cluster. All traffic between services flows through these proxies. Because the proxies sit on the data path, they can:
- Encrypt traffic automatically with mutual TLS, so every service-to-service call is verified and encrypted without changing application code
- Enforce access policy at the network level: Service A can call Service B on port 8080, but not port 8443
- Collect telemetry on every request: latency, error rates, retries, circuit breaker state
- Handle failure modes like retries, timeouts, and circuit breaking without application-level code
The appeal is obvious. You get security, observability, and resilience for free, just by deploying the mesh. In practice, nothing in this list is free.
The Real Cost
The overhead comes in two forms: latency and operational complexity.
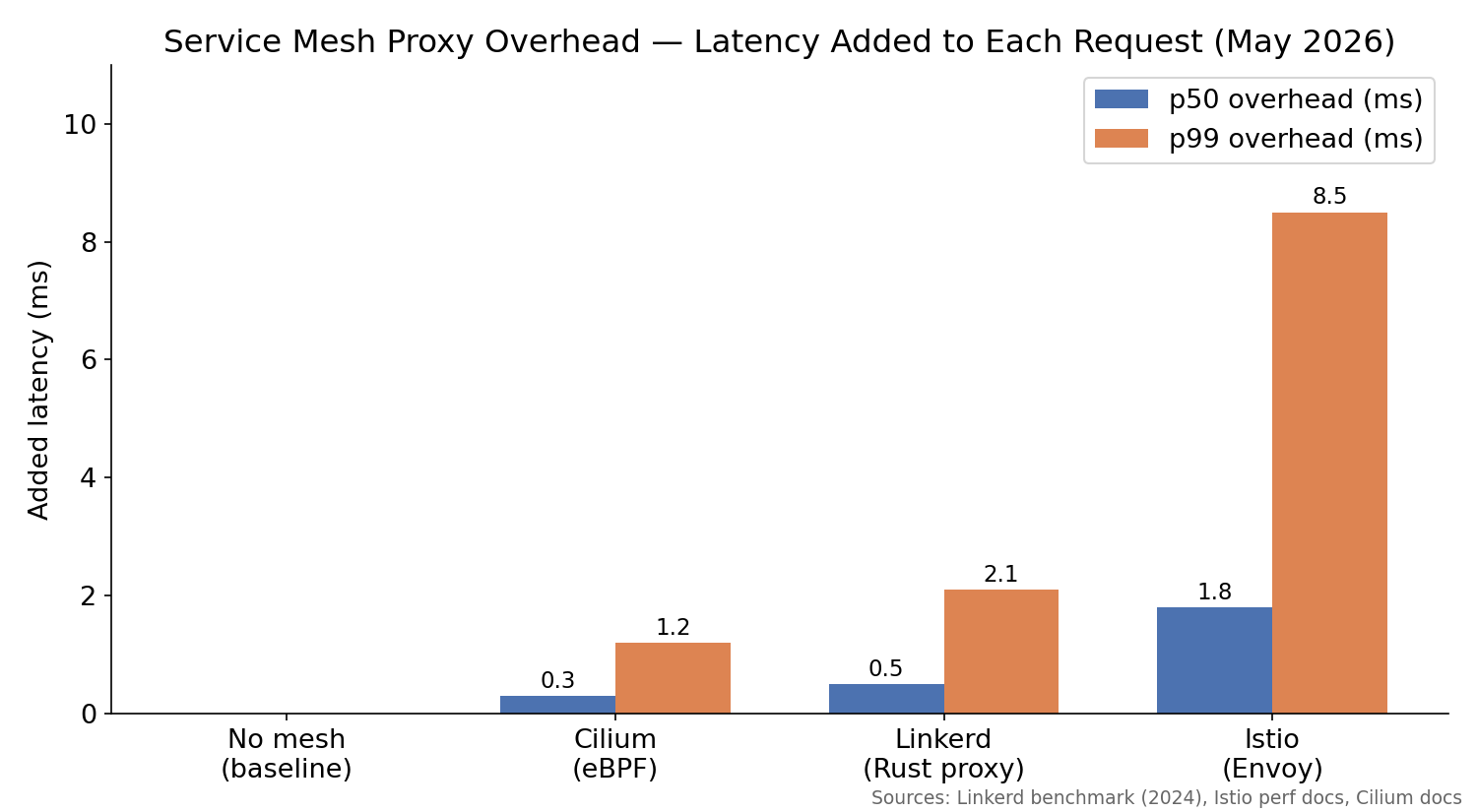
p50 and p99 latency overhead per request. Data from Linkerd’s 2024 benchmark report and Istio’s published performance documentation. Real-world results vary by traffic volume, payload size, and hardware.
Istio’s overhead at p99 is genuinely significant for latency-sensitive workloads. If your application’s p99 baseline is 20ms, adding 8ms for mesh processing is a 40% regression. If your baseline is 2000ms because you’re doing a database query, nobody notices.
The operational cost is harder to quantify. Istio has around 50 custom resource definitions. Its documentation assumes familiarity with Envoy. Debugging a misbehaving DestinationRule or PeerAuthentication policy requires understanding the mesh internals, not just your application. Teams new to Istio routinely spend a day debugging a configuration that took 10 minutes to write.
Linkerd is meaningfully simpler. Cilium, which uses eBPF instead of sidecar proxies, skips the sidecar overhead entirely — which is why its p50 numbers sit closest to the no-mesh baseline.
The Three Options
Istio
Istio is the most-deployed service mesh in production. It was originally developed at Google and Lyft, and it shows — the feature set is enormous, covering traffic management, security, observability, and extensibility in ways the other options don’t match.
What you get: fine-grained traffic control (percentage-based canary splits, header-based routing, fault injection for chaos testing), full mTLS with certificate rotation, Envoy’s complete observability surface, and integration with every major observability platform.
What it costs: sidecars on every pod, a non-trivial control plane (istiod), and configuration complexity that scales faster than your team. The CRDs are expressive but unforgiving. A misconfigured VirtualService silently routes traffic nowhere; figuring out why takes familiarity with istioctl.
Who it’s for: large teams running 20+ services, organizations with compliance requirements that mandate encrypted east-west traffic with audit logging, and anyone who needs the full traffic management surface.
# Istio: route 10% of traffic to a canary deployment
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: product-service
spec:
hosts:
- product-service
http:
- match:
- headers:
x-canary:
exact: "true"
route:
- destination:
host: product-service
subset: v2
- route:
- destination:
host: product-service
subset: v1
weight: 90
- destination:
host: product-service
subset: v2
weight: 10Linkerd
Linkerd is the CNCF-graduated mesh that made “ultralight” its design principle. The sidecar proxy is written in Rust, which is why the latency numbers are lower than Istio. Configuration uses standard Kubernetes annotations rather than custom CRDs for most things, which means less to learn and less to misonfigure.
The tradeoff: Linkerd deliberately does less. It supports mTLS, traffic splitting, retries and timeouts, and solid observability through its dashboard and Prometheus integration. It does not support the advanced traffic management features Istio offers. If you need fine-grained Envoy configuration, Linkerd is the wrong tool.
Who it’s for: teams that want mTLS and basic traffic management without the Istio complexity tax. The Linkerd install is around 10 minutes. Debugging problems is more tractable because there is less machinery to inspect.
# Linkerd is often simpler to start with
linkerd install --crds | kubectl apply -f -
linkerd install | kubectl apply -f -
# Annotate a namespace to inject sidecars automatically
kubectl annotate namespace production linkerd.io/inject=enabledCilium
Cilium uses eBPF programs running in the Linux kernel instead of sidecar proxies. Because the proxying happens at the kernel level, there is no per-pod container to schedule, no extra memory footprint per service, and the latency overhead is the lowest of the three options.
The feature set has grown substantially. Cilium now covers mTLS (via SPIFFE/SPIRE integration), L7 policy enforcement, and rich network observability through Hubble. It also handles network policy at both L3/L4 and L7, which makes it the only option here that does double duty as a Kubernetes CNI plugin and a service mesh.
Who it’s for: teams that want mesh capabilities without sidecar overhead, organizations already evaluating Cilium as their CNI plugin, and anyone running latency-sensitive workloads where every millisecond counts. The operational model is different from the other two — you’re thinking about eBPF and kernel behavior rather than Envoy and CRDs — which is either more or less familiar depending on your background.
The Decision Framework
Rather than comparing features side by side, here is the question sequence that actually produces the right answer:
1. Do you have a network security requirement for service-to-service encryption?
If your compliance requirements mandate encrypted east-west traffic and you need auditability, a service mesh is one route to get there. (Network-level encryption via a VPN overlay like Tailscale is another, cheaper route for smaller setups.) If you don’t have this requirement, the security justification for a mesh is weaker than it appears — your cloud VPC already provides network-level isolation.
2. Are your services calling each other directly, and do you have reliability problems?
Service meshes help with retry logic, circuit breaking, and timeout enforcement. But if you have two services, you can handle this in your HTTP client. If you have fifteen services with complex call graphs and cascading failures, a mesh makes the reliability logic declarative and consistent. The threshold is roughly 8-10 services with non-trivial interdependencies.
3. Is your observability blind at the service-to-service level?
A mesh’s telemetry is genuinely useful — you get latency percentiles, error rates, and request volumes between every pair of services without touching application code. But Prometheus, structured logging, and OpenTelemetry instrumentation can get you most of this without a mesh. If you already have decent observability, the mesh telemetry is additive, not transformative.
4. Can your team absorb the operational load?
This is the question teams skip. A service mesh adds a system to understand, upgrade, and debug. Istio has a release cycle. Certificates rotate and sometimes fail to rotate. Upgrades require coordination. If your team has two platform engineers and they are already stretched, a mesh is more likely to become a maintenance burden than an asset.
| Team size | Service count | Verdict |
|---|---|---|
| 1-5 engineers | < 10 services | Skip the mesh. Use your cloud provider’s VPC, standard HTTP clients for retries, and OpenTelemetry. |
| 5-15 engineers | 10-30 services | Linkerd if you need mTLS. Cilium if you want to go all-in on eBPF and are already choosing a CNI. |
| 15+ engineers | 30+ services | Evaluate Istio. The feature surface starts paying off at this scale. |
Starting Without One
If you’re not sure yet, here is what handles the main use cases without a mesh:
Encryption: Cloud VPCs provide L3 isolation. For explicit mTLS, SPIFFE/SPIRE runs without a full mesh, and most cloud providers offer service-to-service auth natively (AWS IAM roles for ECS/EKS service accounts, GKE Workload Identity).
Retries and circuit breaking: Libraries like resilience4j (Java), tenacity (Python), or axios-retry (Node.js) handle this at the client level. It’s more code, but it’s code you understand.
Observability: OpenTelemetry instrumentation, Prometheus, and a log aggregator (Loki, Datadog, whatever your org uses) cover most of what a mesh’s telemetry provides, with more control over what you measure.
Traffic splitting: Your ingress controller (nginx, Traefik, Kong, AWS ALB) handles blue-green and canary deployments at the edge. For internal services, feature flags or application-level routing work fine.
If You Do Adopt One
Whichever mesh you choose, a few things hold across all of them:
Start with a single non-production namespace. Inject the mesh into staging first and run it for a few weeks before touching production. This catches certificate expiry issues, version conflicts with your k8s version, and configuration mistakes before they affect customers.
Monitor the control plane as carefully as the data plane. The mesh’s health checks are not the same as your application’s health checks. Istiod going unhealthy while sidecars continue working on their cached config is a silent failure mode that bites teams during upgrades.
Version-pin everything. Mesh upgrades are not always backwards-compatible. Pin your mesh version in your GitOps config and test upgrades explicitly.
Set resource limits on sidecar containers. Linkerd and Istio inject sidecars without resource limits by default in some configurations. A runaway sidecar can OOM-kill the pod it’s supposed to protect.
A service mesh is not wrong. It is also not automatically right. The teams who get the most out of meshes are the ones who adopted them in response to a specific problem, not in anticipation of one.
Sponsored
More from this category
More from Cloud & Infrastructure
 R.01
R.01 Database Connection Pooling in 2026: PgBouncer, Supabase, and Prisma Accelerate
 R.02
R.02 Secrets Management in Production: The Patterns That Actually Work
R.03 Incident Response for Small Engineering Teams: SRE Without a Dedicated Ops Team
Sponsored
The dispatch
Working notes from
the studio.
A short letter twice a month — what we shipped, what broke, and the AI tools earning their keep.
Discussion
Join the conversation.
Comments are powered by GitHub Discussions. Sign in with your GitHub account to leave a comment.
Sponsored