AI Integration · Industry News
DeepSeek V4: Inside the 1-Trillion Parameter Open-Source Model Poised to Reshape AI
DeepSeek's V4 model brings 1 trillion parameters, Engram conditional memory, and open-source weights under Apache 2.0. We break down the architecture, coding benchmarks, geopolitical implications, and what it means for developers.

Anurag Verma
9 min read

The gap between closed-source AI giants and open-source challengers is not just closing — it may be inverting. DeepSeek, the Chinese AI research lab that sent shockwaves through the industry with its V3 model in late 2025, is preparing to release DeepSeek V4: a 1-trillion parameter Mixture-of-Experts model that reportedly outperforms GPT-4.5 Turbo on coding and logic tasks while running at 40% of the inference cost. And it is releasing the weights under an Apache 2.0 license.
Slated for release around February 17, 2026, DeepSeek V4 is specifically designed to dominate the “autonomous coding” sector — moving beyond simple snippet generation to managing entire software repositories with what the company describes as human-level reasoning. Here is everything we know about the model, its architecture, and what it means for developers worldwide.
Architecture: The 1-Trillion Parameter MoE System
DeepSeek V4 is a Mixture-of-Experts (MoE) model with a total parameter count of approximately 1 trillion. But here is the critical detail: for any given token, only approximately 32 billion parameters are activated. This “Top-16” routed MoE strategy allows the model to maintain the specialized knowledge of a titan-class system without the crippling latency or hardware requirements usually associated with models of this scale.
To put this in perspective:
| Model | Total Parameters | Active Parameters | Architecture |
|---|---|---|---|
| GPT-4.5 Turbo | ~1.8T (estimated) | Unknown (closed) | Dense/MoE (unconfirmed) |
| Claude Opus 4.6 | Unknown (closed) | Unknown (closed) | Unknown (closed) |
| Llama 4 Behemoth | 2T | ~288B | MoE |
| DeepSeek V4 | ~1T | ~32B | MoE (Top-16) |
The efficiency implications are staggering. By activating only 32 billion parameters per token, V4 can run on hardware that would be insufficient for a dense model of equivalent capability. This directly translates to lower inference costs and faster response times.
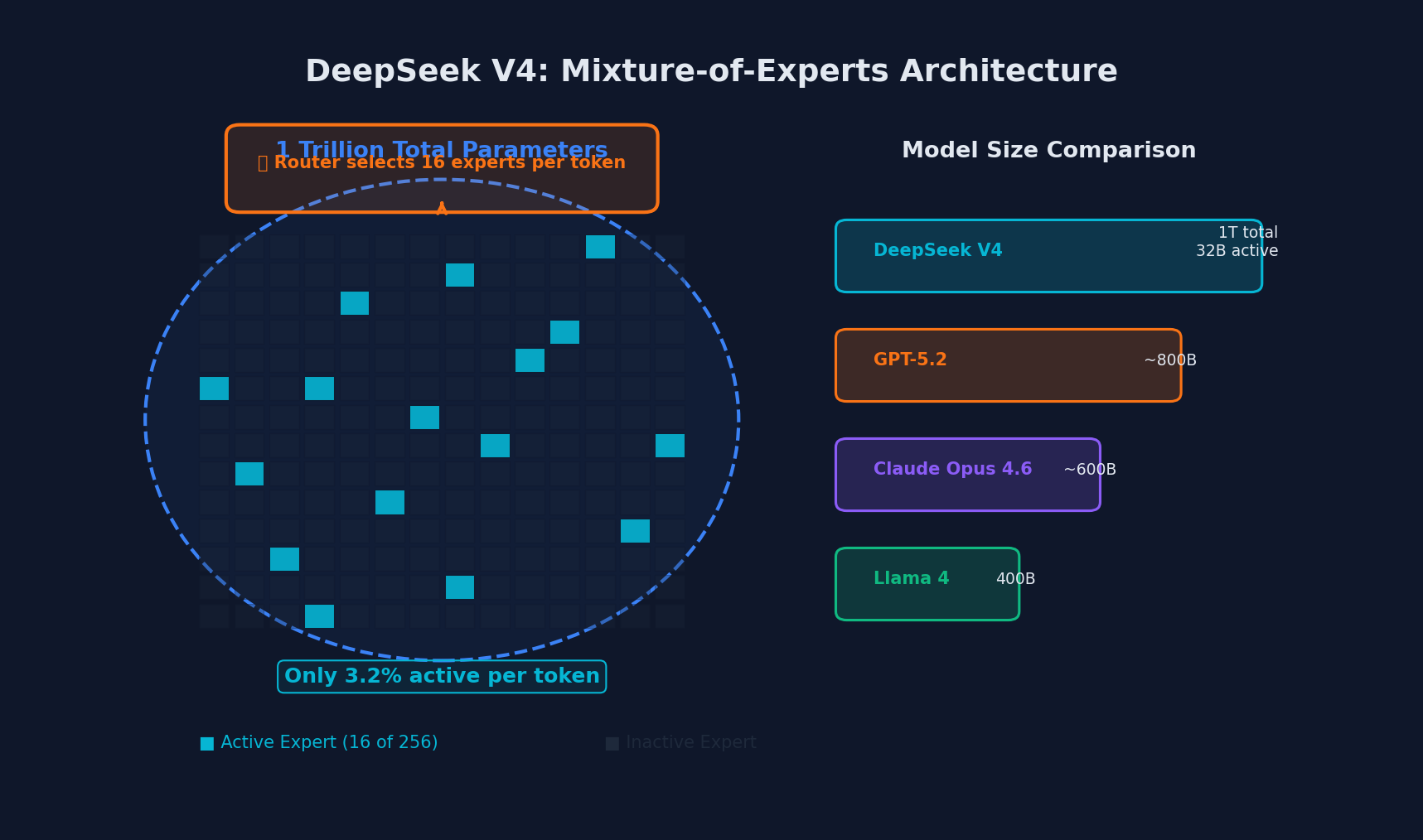 DeepSeek V4’s MoE architecture: 1 trillion parameters, only 32B active per token
DeepSeek V4’s MoE architecture: 1 trillion parameters, only 32B active per token
Three Architectural Innovations
1. Engram Conditional Memory
The headline innovation in V4 is the “Engram” conditional memory module. Published as a research paper in January 2026, Engram represents a fundamental rethinking of how large language models handle knowledge retrieval versus active reasoning.
Traditional LLMs store all knowledge — from basic syntax rules to complex reasoning chains — in the same GPU-resident transformer weights. This is inherently wasteful: recalling that Array.prototype.map() takes a callback function does not require the same computational machinery as reasoning about a complex race condition.
Engram separates these concerns:
- Static factual knowledge (syntax, library APIs, well-known patterns) is offloaded to system RAM (DRAM) using an O(1) lookup system
- GPU VRAM is preserved for complex reasoning, multi-step planning, and novel problem-solving
- The result is 97% long-context accuracy with dramatically reduced GPU memory requirements
# Conceptual illustration of Engram's dual-path architecture
# (simplified for understanding - not actual implementation)
class EngramConditionalMemory:
def __init__(self):
self.static_knowledge = DRAMHashTable() # O(1) lookups in system RAM
self.reasoning_engine = GPUTransformer() # Complex reasoning on GPU
def process(self, query, context):
# Route based on query complexity
complexity = self.classify_query(query)
if complexity == "factual_recall":
# Fast path: O(1) lookup for known facts
return self.static_knowledge.lookup(query)
else:
# Reasoning path: full transformer computation
return self.reasoning_engine.reason(query, context)This architecture has a secondary benefit that is particularly relevant given the geopolitical context: by reducing HBM (High Bandwidth Memory) requirements, Engram enables competitive model deployment on hardware that is available despite U.S. export controls on cutting-edge GPUs.
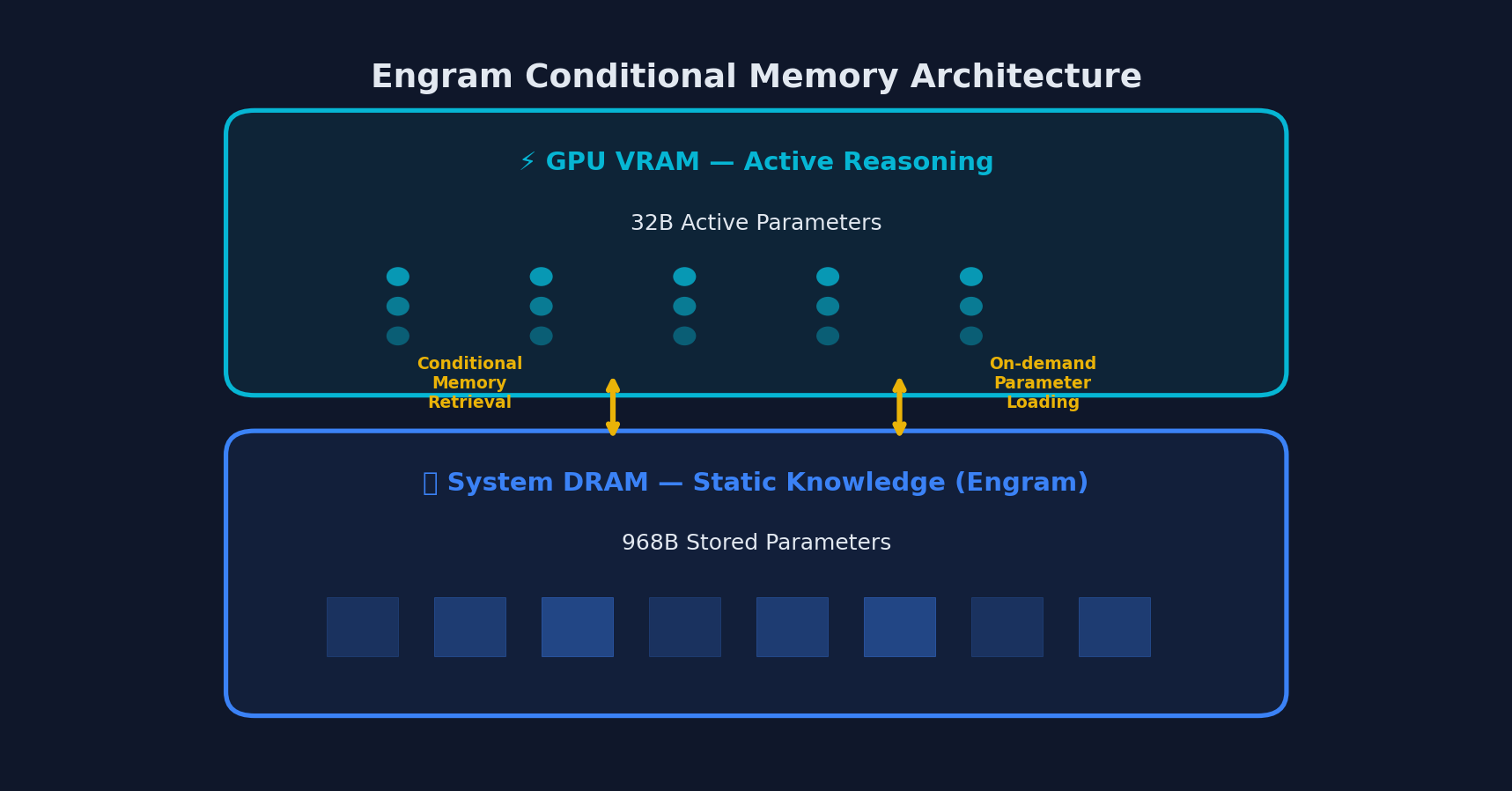 The Engram memory system splits parameters between GPU VRAM and system DRAM
The Engram memory system splits parameters between GPU VRAM and system DRAM
2. Manifold-Constrained Hyper-Connections (mHC)
V4 introduces Manifold-Constrained Hyper-Connections, a novel approach to information flow between transformer layers. While the full technical details are still emerging, the core idea is to create structured shortcut connections between layers that are constrained to lie on learned manifolds — ensuring that information can flow efficiently across the model’s depth without the gradient degradation problems that plague very deep networks.
The practical impact: more effective use of the model’s depth, enabling better performance on tasks that require extended chains of reasoning.
3. DeepSeek Sparse Attention
V4’s attention mechanism enables context windows exceeding 1 million tokens while reducing computational costs by approximately 50% compared to standard attention mechanisms. This is achieved through a learned sparse attention pattern that identifies and focuses on the most relevant portions of the context for each query, rather than attending to all tokens equally.
For coding tasks, this means V4 can hold an entire large codebase in context and still efficiently locate the relevant files and functions for a given task.
Coding Benchmarks
DeepSeek’s internal testing — while not yet independently verified at the time of writing — shows remarkable results:
| Benchmark | DeepSeek V4 | Claude Opus 4.6 | GPT-5.3 Codex |
|---|---|---|---|
| SWE-Bench Verified | ~80%+ (reported) | 79.4% | 76.1% |
| HumanEval | 90% | 88% (estimated) | ~92% |
| Multi-file repo tasks | Strong (per reports) | Strong | Strong |
If the SWE-Bench Verified score of 80%+ holds up under independent evaluation, V4 would represent the state of the art for open-source models on this benchmark — and would be competitive with or ahead of the best closed-source models.
Open Source: Apache 2.0
DeepSeek has committed to releasing V4 Base under the Apache 2.0 license, continuing its tradition of open-weight releases. This is significant for several reasons:
What “Open” Means (and Does Not Mean)
It is important to be precise about what DeepSeek is releasing:
- Model weights: Released under Apache 2.0. You can download, modify, fine-tune, and deploy commercially.
- Training code: Partially available. The core architecture and training loops are published.
- Training data: Not disclosed. DeepSeek has not released details about its training data composition.
- Fine-tuning methodologies: Some details withheld.
- RLHF/alignment data: Not released.
This makes V4 “open-weight” rather than fully “open-source” in the strictest sense. But for practical developer use — downloading the model and running it locally or deploying it on your own infrastructure — Apache 2.0 weights are what matters.
Running V4 Locally
Thanks to the MoE architecture with only 32B active parameters, V4 will be runnable on surprisingly accessible hardware:
# Expected hardware requirements for local inference
# (based on V3 extrapolation and 32B active parameters)
# Minimum viable setup (slow but functional):
# - 64GB system RAM
# - Single NVIDIA A100 80GB or equivalent
# - NVMe SSD for weight loading
# Recommended setup for reasonable speed:
# - 128GB system RAM (for Engram static knowledge)
# - 2x NVIDIA A100 80GB or 1x H100
# - NVMe RAID for fast weight loading
# Example: Running with vLLM (expected support)
pip install vllm>=0.7.0
python -m vllm.entrypoints.openai.api_server \
--model deepseek-ai/DeepSeek-V4 \
--tensor-parallel-size 2 \
--max-model-len 131072 \
--trust-remote-codeFor developers who do not have access to this hardware, DeepSeek’s API will offer access at prices that are expected to be significantly lower than comparable closed-source alternatives — continuing the pricing pressure that V3 initiated.
The Geopolitical Context
DeepSeek V4 cannot be discussed without acknowledging the broader U.S.-China AI competition in which it exists.
U.S. Export Controls
The United States has implemented increasingly stringent export controls on advanced AI chips, specifically targeting the high-bandwidth memory and compute capabilities needed to train and run frontier AI models. DeepSeek’s architectural innovations — particularly Engram’s reduction of HBM requirements — can be read as a direct response to these constraints.
By engineering a model that achieves competitive performance with less capable hardware, DeepSeek is demonstrating that export controls may slow but cannot stop Chinese AI development. The Engram approach of offloading static knowledge to cheaper, unrestricted DRAM is an elegant technical workaround to a hardware constraint.
Implications for the AI Ecosystem
The release of V4 under Apache 2.0 has several downstream effects:
-
Pricing pressure: Open-source models set a floor for what closed-source providers can charge. If V4 is truly competitive with GPT-5.3 and Opus 4.6, it will be difficult for OpenAI and Anthropic to justify premium pricing for comparable capability.
-
Sovereignty: Organizations and governments that cannot or do not want to depend on U.S.-based AI providers now have a viable alternative. This is particularly relevant for developers in Europe, Southeast Asia, and other regions navigating AI sovereignty concerns.
-
Research acceleration: Open weights enable the global research community to study, improve, and build upon the model in ways that are impossible with closed-source systems.
-
Security scrutiny: Open weights also mean open security scrutiny. The model’s behavior, biases, and potential misuse vectors can be studied by independent researchers — a transparency advantage over closed alternatives.
What This Means for Developers
Evaluate V4 for Your Use Case
When V4 drops, do not just benchmark it on toy problems. Test it against your actual codebase, your actual tasks, and your actual quality bar:
# Example: Evaluating V4 against your codebase
import openai # DeepSeek API is OpenAI-compatible
client = openai.OpenAI(
base_url="https://api.deepseek.com/v1",
api_key="your-deepseek-api-key"
)
# Test with a real task from your backlog
response = client.chat.completions.create(
model="deepseek-v4",
messages=[
{"role": "system", "content": "You are a senior software engineer."},
{"role": "user", "content": """
Review this pull request and identify any bugs,
security issues, or performance problems:
[paste your actual PR diff here]
"""}
],
max_tokens=4096
)
print(response.choices[0].message.content)Consider Self-Hosting
If your organization handles sensitive code or has data residency requirements, V4’s open weights mean you can run the entire model on your own infrastructure with zero data leaving your network. This is something no closed-source provider can offer.
Watch the Independent Benchmarks
DeepSeek’s self-reported numbers are promising but unverified. Wait for independent evaluations from organizations like the LMSYS Chatbot Arena, Holistic Evaluation of Language Models (HELM), and community benchmarks on HuggingFace before making strategic decisions.
The Bottom Line
DeepSeek V4 represents a potential inflection point in the AI landscape. A 1-trillion parameter model with open weights, novel architecture, and reportedly state-of-the-art coding performance — released under Apache 2.0 — challenges the assumption that frontier AI capability requires frontier AI pricing and closed ecosystems.
Whether you are bullish or skeptical, V4 deserves serious attention from every developer and engineering leader. The model drops around February 17, 2026. Mark your calendar.
More from this category
More from AI Integration
 R.01
R.01 Google Workspace Gets a Major AI Boost: Gemini Now Powers Docs, Sheets, Slides & Drive
R.02 Agentic AI in 2026: Inside Google's Agent Leap Report and the Rise of Autonomous AI
 R.03
R.03 Best AI Coding Models Compared: The Definitive February 2026 Guide
The dispatch
Working notes from
the studio.
A short letter twice a month — what we shipped, what broke, and the AI tools earning their keep.
Discussion
Join the conversation.
Comments are powered by GitHub Discussions. Sign in with your GitHub account to leave a comment.