AI Integration · LLM Engineering
LLM Hallucination in Production: Mitigation Strategies That Actually Work
Hallucination is not a bug that gets patched in the next model release. It is a property of how language models work. Here are the patterns that actually reduce it in production systems, and what they cost.

Anurag Verma
8 min read

Sponsored
Every team building on top of an LLM eventually hits the same wall: the model confidently states something that isn’t true. A customer service bot invents a product feature. A legal assistant cites a case that doesn’t exist. A coding assistant generates an API call with a method signature that was never in the docs.
The temptation is to treat hallucination as a defect in the current model that the next release will fix. It won’t. Hallucination is a consequence of how autoregressive language models work: they predict probable continuations of text, not verified truth. Better models hallucinate less, but they still hallucinate, and they often do so more confidently, which is sometimes worse.
The only real mitigation is architecture. Here is what actually works.
Why Hallucination Happens
Understanding the mechanism helps decide which mitigation to apply. A language model generates output by predicting the most likely next token given the context. It has no mechanism for distinguishing “I know this” from “I’m making this up.” The training process rewards fluent, coherent outputs, not accurate ones.
The situations that produce the most hallucination:
- Questions outside the training distribution (very recent events, niche domains)
- Questions where a plausible-sounding wrong answer exists alongside the correct one
- Long-form outputs where the model has to maintain factual consistency across many tokens
- Requests to cite sources (models learn citation formats, not actual citations)
The Pipeline View
Rather than relying on a single fix, production systems that handle hallucination well layer multiple mitigations. Each layer reduces blast radius; none eliminates the problem on its own.
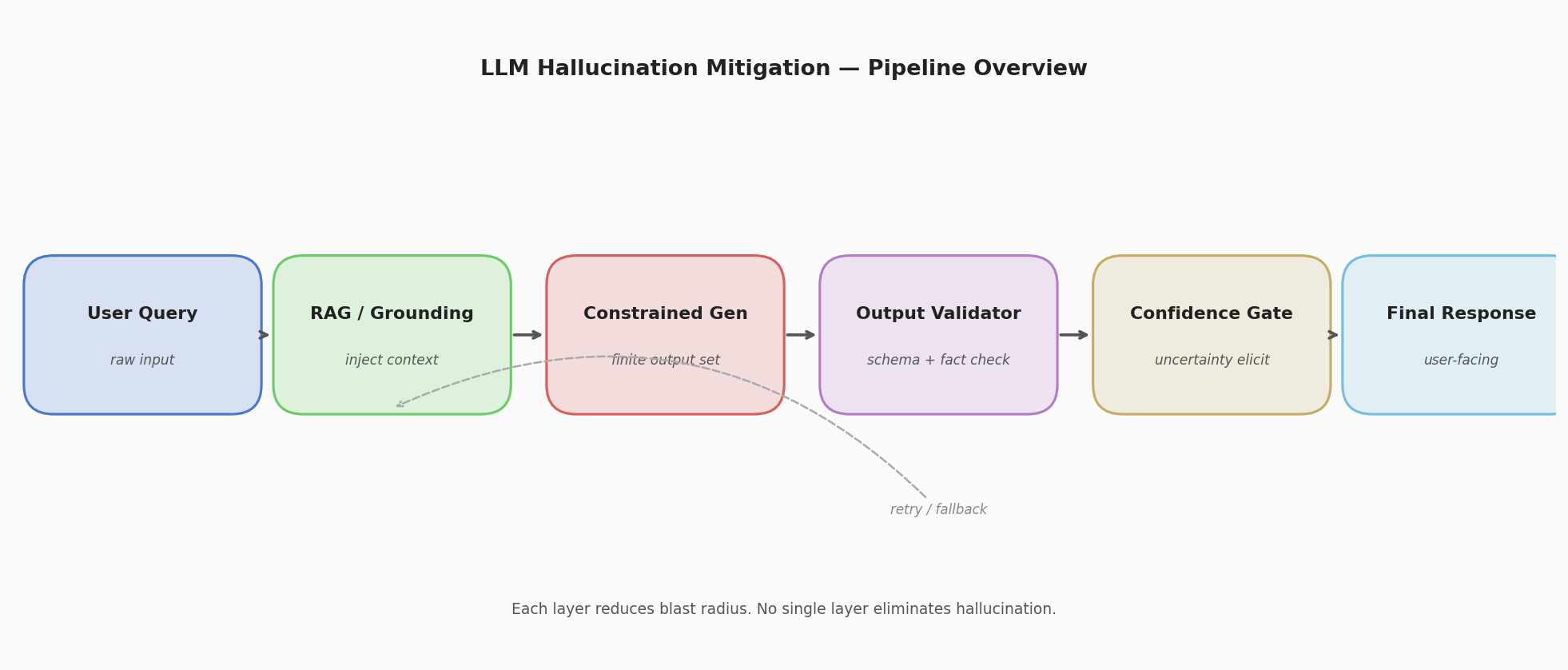
The rest of this post covers each layer in order.
Layer 1: Retrieval-Augmented Generation (RAG)
RAG is the most common mitigation for knowledge-based applications. Instead of asking the model to answer from parametric memory (what it learned during training), you retrieve relevant documents at query time and provide them as context.
async def answer_question(question: str) -> str:
# Retrieve relevant documents
relevant_docs = await vector_store.similarity_search(
query=question,
k=5,
score_threshold=0.7, # Only use if above similarity threshold
)
if not relevant_docs:
return "I don't have information on that topic."
context = "\n\n".join([
f"Source: {doc.metadata['source']}\n{doc.page_content}"
for doc in relevant_docs
])
prompt = f"""Answer the question using only the provided sources.
If the sources don't contain enough information to answer, say so.
Do not add information not present in the sources.
Sources:
{context}
Question: {question}"""
return await llm.generate(prompt)RAG reduces hallucination for questions answerable from your document corpus. It doesn’t help when:
- The question is outside the corpus
- The retrieval step returns irrelevant documents (garbage in, garbage out)
- The model ignores the context and answers from parametric memory anyway
The retrieval quality matters as much as the generation. A model grounded in bad context will still produce wrong answers. Invest in chunking strategy, embedding quality, and retrieval evaluation before optimizing the generation step.
Layer 2: Constrained Generation
When the set of valid outputs is finite, constrain the model to that set. Instead of letting the model generate free text and then checking it, force the output into a structure that can only contain valid values.
ORDER_STATUSES = ["pending", "processing", "shipped", "delivered", "cancelled"]
response = await llm.generate(
prompt=f"""Order data: {order_json}
Classify this order's current status.
Respond with exactly one word from this list: {', '.join(ORDER_STATUSES)}
No explanation. One word only.""",
max_tokens=10,
stop=["\n", " ", "."],
)
status = response.strip().lower()
assert status in ORDER_STATUSES, f"Unexpected status: {status}"For classification, extraction, and routing tasks, constrained generation eliminates most hallucination by making invalid outputs structurally impossible. This is the highest-confidence mitigation available — it works by removing the space for the model to be wrong.
Layer 3: Output Validation
For structured outputs — JSON, specific data formats, factual claims that can be checked programmatically — validate before returning to the user.
from pydantic import BaseModel, field_validator
from typing import List
import re
class MedicalSummary(BaseModel):
diagnosis: str
icd_code: str
confidence: float
citations: List[str]
@field_validator('icd_code')
@classmethod
def validate_icd_code(cls, v):
if not re.match(r'^[A-Z]\d{2}\.?\d{0,3}$', v):
raise ValueError(f'Invalid ICD-10 code format: {v}')
return v
@field_validator('citations')
@classmethod
def citations_required(cls, v):
if not v:
raise ValueError('Citations are required for medical summaries')
return v
async def generate_medical_summary(notes: str) -> MedicalSummary:
for attempt in range(3):
try:
raw_output = await llm.generate_structured(
prompt=f"Summarize these clinical notes: {notes}",
output_schema=MedicalSummary.model_json_schema(),
)
return MedicalSummary.model_validate_json(raw_output)
except (ValueError, ValidationError) as e:
if attempt == 2:
raise RuntimeError(f"Failed to generate valid summary: {e}")
# Feed the error back on the next attemptFor factual claims you can check against an external source — product prices, policy details, specific dates — validate programmatically against the authoritative source. Don’t ask the model to check itself; it will often confirm its own hallucination.
Layer 4: Self-Consistency and Voting
For high-stakes outputs where you can afford the cost, generate multiple responses and check for consistency. Inconsistent answers across runs signal low confidence.
import asyncio
from collections import Counter
async def high_stakes_answer(question: str, n: int = 3) -> dict:
responses = await asyncio.gather(*[
llm.generate(question) for _ in range(n)
])
answers = [extract_key_claim(r) for r in responses]
vote_counts = Counter(answers)
top_answer, top_count = vote_counts.most_common(1)[0]
return {
"answer": top_answer,
"confidence": top_count / n,
"consistent": top_count >= (n * 0.67), # 2/3 agreement threshold
"all_responses": responses,
}Self-consistency works well for mathematical reasoning, factual lookups, and classification. It doesn’t work well for creative or open-ended generation where variation is expected and not a signal of uncertainty.
The cost tradeoff is real. Generating 3 responses costs 3x. For low-stakes questions, this isn’t worth it. For financial, medical, or legal outputs, the cost of a confident wrong answer often exceeds 3x the API cost.
Layer 5: Uncertainty Elicitation
Ask the model to express uncertainty explicitly, then act on that signal:
prompt = """Answer the following question.
After your answer, rate your confidence on a scale of 1-10,
where 1 = highly uncertain or likely wrong, 10 = very confident.
If your confidence is below 7, explain specifically what you're uncertain about.
Format your response as:
ANSWER: [your answer]
CONFIDENCE: [1-10]
UNCERTAINTY: [blank if confident, specific explanation if not]
Question: {question}"""This doesn’t eliminate hallucination, but it surfaces cases where the model itself signals uncertainty. Use those signals to trigger fallbacks: show a disclaimer, route to a human reviewer, or decline to answer rather than showing a low-confidence response.
Calibration varies by model. Some models over-express confidence (say 9/10 on answers they’re wrong about). Evaluate your model’s uncertainty calibration on a test set before relying on self-reported confidence.
What Doesn’t Work
Prompting “do not hallucinate.” Instruction-tuned models will follow this instruction and still hallucinate. They don’t have a reliable internal mechanism to detect when they’re doing it.
Asking the model to cite sources without providing them. Models learn the format of citations well enough to generate plausible-looking fake ones. “Please cite your sources” produces hallucinated citations at roughly the same rate as unconstrained answers produce hallucinated facts.
Believing model self-correction. “Are you sure that’s correct?” often produces a different wrong answer rather than the right one. The model shifts to whatever the new most-probable token sequence is given the added context, which is not the same as the correct answer.
Version hopping to fix specific hallucinations. Upgrading models to reduce a specific hallucination pattern often shifts it rather than eliminating it. Invest in the architectural mitigations; they work across model versions.
Putting It Together
No single mitigation is a complete solution. The production systems that handle hallucination well combine multiple layers:
- RAG or tool use to provide grounded context for questions that have definite answers
- Constrained generation for classification and extraction tasks
- Structured output with validation to catch format violations before they reach users
- Uncertainty elicitation for high-stakes outputs with a fallback path for low-confidence answers
- Human review or an explicit “I don’t know” response for questions where the risk of being wrong is high and the domain is outside the grounding corpus
The cost of these layers varies. RAG requires infrastructure. Validation adds latency. Voting multiplies API costs. The right combination depends on the stakes of being wrong in your specific application.
The teams that handle hallucination best don’t try to eliminate it completely — they design systems where a hallucination has limited blast radius, is likely to be caught before reaching a user, and fails gracefully when it does get through.
Sponsored
More from this category
More from AI Integration
 R.01
R.01 AI in E-Commerce: What's Actually Working in 2026
 R.02
R.02 AI-Assisted Technical Documentation: Keeping Docs Accurate When Code Changes Fast
R.03 The Vercel AI SDK in 2026: Streaming, Tool Calls, and Multi-Step Agents
Sponsored
The dispatch
Working notes from
the studio.
A short letter twice a month — what we shipped, what broke, and the AI tools earning their keep.
Discussion
Join the conversation.
Comments are powered by GitHub Discussions. Sign in with your GitHub account to leave a comment.
Sponsored